Introduction
One of the frequently used and the most popular features in SQLServer is the ability to create a table on the fly based on a query. This has saved my day on numerous occasions. Only thing I was missing in this was the ability to organize the table into its own filegroup of my choice
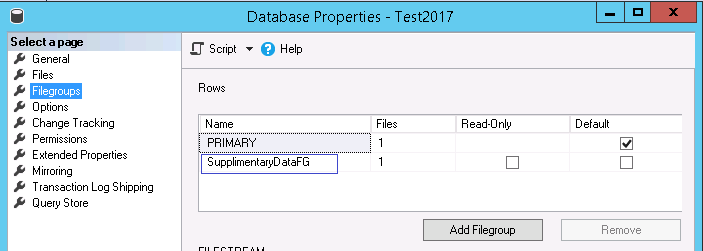
Why are filegroups necessary?
There are various advantages of organizing tables into separate filegroups, the main among them being the below
- For large tables it makes sense to move them to a separate filegroup
- In case of tables where data size is almost same as non-clustered index size, we shall consider keeping table in one file group and index on another
- Organizing tables based on portfolio so that tables can be easily migrated / archived if required.
- Maintaining some data which is read only along with read write data in same db. In this case we can keep these tables in a separate read only file group
The Solution
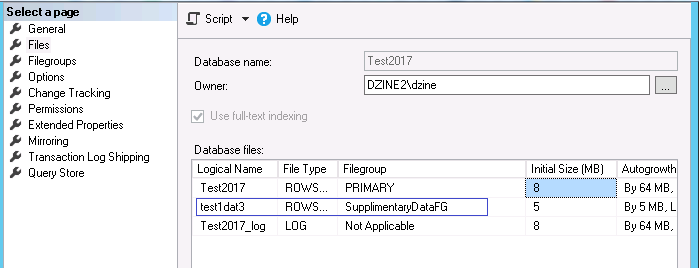
The SQL 2017 CTP2 release includes a solution to the above limitation.
The SELECT … INTO syntax for creating the table is now extended to include the filegroup information.
The modified syntax would be like below
SELECT column1, column2,.. columnN
INTO NewTableName
ON FileGroupName
FROM Table1 t1
JOIN Table2 t2
ON condition…
…
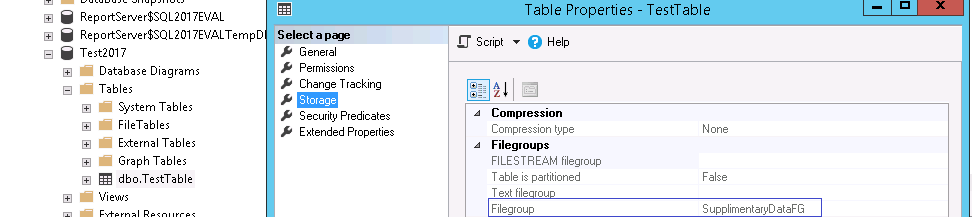
If you see the code above, the highlighted part designates the filegroup to which this new table has to be associated. Only caveat is that the filegroup must pre-exist in the database where the above query is being executed otherwise SQLServer will throw an error
Illustration
SELECT * INTO TestTable
ON SupplimentaryDataFG
FROM
(VALUES
(‘Test’,1),
(‘Foo’,2),
(‘Foobar’,3)
)t(Description,Code)