I’m back with another scenario regarding text file data transfer.
The impetus to writing this blog was recent mail I got from one of my blog followers. He had a scenario which he wanted me to provide him with a solution with.
The scenario here was a multipart file containing the details of orders. The file has three different types of row indicating order header information, the details and also the summary information. The metadata of the three types of rows are different so it was not possible to use a standard data flow task with flat file source to process and get the data from the file. Also the file data has to go into three separate tables set up in the database which also have referential integrity set up through foreign key constraints. As always with requirements of this type, they had little control over how the file was getting generated from the source.
I suggested a work around for handling the scenario which I’m sharing here
The file looked like this

The impetus to writing this blog was recent mail I got from one of my blog followers. He had a scenario which he wanted me to provide him with a solution with.
The scenario here was a multipart file containing the details of orders. The file has three different types of row indicating order header information, the details and also the summary information. The metadata of the three types of rows are different so it was not possible to use a standard data flow task with flat file source to process and get the data from the file. Also the file data has to go into three separate tables set up in the database which also have referential integrity set up through foreign key constraints. As always with requirements of this type, they had little control over how the file was getting generated from the source.
I suggested a work around for handling the scenario which I’m sharing here
The file looked like this
As you see from the above the file consists of three types of rows. The rows starting with H designates the Order Header information and consists of column values for OrderNo,OrderDate and CustomerName columns.The rows starting with D indicates the details of the order which includes ItemName,PartNo for the item,Quantity ordered,UnitPrice of the item and also the Shipset number (Shipset represents a unit of deivery for the Order). Finally the rows with S represents Order Summary information with latest Delivery Date (of the last shipset) and Total Order Value. So group of rows from H till the following S represents the details of a single order and have to be stored against same reference ID value (OrderHeaderID).
The data from the above file has to go into the below tables in database
OrderHeader (OrderHeaderID (PK IDENTITY),OrderNo,OrderDate,CustomerName)
OrderDetails (OrderHeaderID(FK to OrderHeader),ItemName,PartNo,Qty,UnitPrice,ShipsetNo)
OrderSummary(OrderHeaderID(FK to OrderHeader),LatestDeliveryDate,OrderTotal)
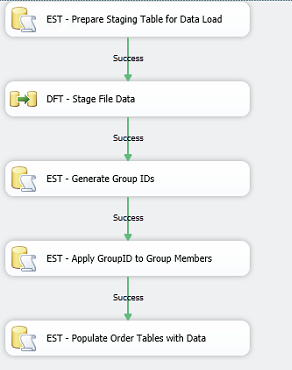
The package for this looks like below
The steps involved are
1. Execute SQL task for truncating and preparing StagingTable for data load. The Staging table will have a RowID column with IDENTITY property
2. Data Flow Task to load the staging table with file data into a single data column in comma separated format
3. Execute SQL tasks to generate the group ids for identifying the header,details and summary rows belong to each group. This is done in two steps. First header rows are assigned a sequential value and then use to apply to following detail and summary rows
The logic looks like below
UPDATE t
SET Grp =Seq
FROM
(
SELECT *,ROW_NUMBER() OVER (ORDER BY RowID) AS Seq
FROM StagingTable
WHERE LEFT(DataColumn,CHARINDEX(‘,’,DataColumn)-1) = ‘H’
)t
UPDATE t
SET Grp= t1.Grp
FROM StagingTable t
CROSS APPLY (SELECT TOP 1 Grp
FROM StagingTable
WHERE Grp IS NOT NULL
AND RowID < t.RowID
ORDER BY RowID DESC) t1
WHERE t.Grp IS NULL
The logic orders the records on the basis of RowID value, generates a sequence ID value using ROW_NUMBER function and assigns it to the header (H) rows. This is followed by a further update statement which assigns the GroupID to the corresponding details and summary rows which comes after the header row. So at the end of this step all rows belonging to a single order will get the same group id value. This is required for applying the newly generated orderheader id (IDENTITY value) from OrderHeader table to each of details and summary rows for the order while doing final data population
4. Execute SQL task to execute procedure to do the final data load with logic as below
CREATE PROC PopulateOrderTableData
AS
DECLARE @INSERTED_ORDERS table
(
OrderHeaderID int,
GrpID int
)
IF OBJECT_ID(‘tempdb..#Headers’) IS NOT NULL
DROP TABLE #Headers
IF OBJECT_ID(‘tempdb..#Details’) IS NOT NULL
DROP TABLE #Details
IF OBJECT_ID(‘tempdb..#Summary’) IS NOT NULL
DROP TABLE #Summary
SELECT RowID,Grp,[1],[2],[3],[4]
INTO #Headers
FROM StagingTable s
CROSS APPLY dbo.ParseValues(s.DataColumn,’,’)f
PIVOT (MAX(Val) FOR ID IN ([1],[2],[3],[4]))p
WHERE [1] = ‘H’
SELECT RowID,Grp,[1],[2],[3],[4],[5],[6]
INTO #Details
FROM StagingTable s
CROSS APPLY dbo.ParseValues(s.DataColumn,’,’)f
PIVOT (MAX(Val) FOR ID IN ([1],[2],[3],[4],[5],[6]))p
WHERE [1] = ‘D’
SELECT RowID,Grp,[1],[2],[3]
INTO #Summary
FROM StagingTable s
CROSS APPLY dbo.ParseValues(s.DataColumn,’,’)f
PIVOT (MAX(Val) FOR ID IN ([1],[2],[3]))p
WHERE [1] = ‘S’
MERGE INTO OrderHeader t
USING #Headers s
ON 1=2
WHEN NOT MATCHED THEN
INSERT (OrderNo ,OrderDate ,CustomerName)
VALUES (s.[2],s.[3],s.[4])
OUTPUT INSERTED.OrderHeaderID,s.Grp INTO @INSERTED_ORDERS;
INSERT OrderDetails
SELECT i.OrderHeaderID,[2],[3],[4],[5],[6]
FROM #Details d
INNER JOIN @INSERTED_ORDERS i
ON i.GrpID = d.Grp
INSERT OrderSummary
SELECT i.OrderHeaderID,[2],[3]
FROM #Summary d
INNER JOIN @INSERTED_ORDERS i
ON i.GrpID = d.Grp
The procedure created three temporary tables #Header,#Details and #Summary and populates them with header,details and summary rows of file data. The logic makes use of UDF ParseValues explained here http://visakhm.blogspot.in/2010/02/parsing-delimited-string.html
to parse the column separated data from the table field into separate values and pivoted into multiple columns.
Then it makes use of a dummy MERGE statement to do insertion to OrderHeader table and captures the generated OrderHeaderID values along with corresponding Grp values to a table variable. The MERGE statement is necessary because we need to capture Grp value from source table along with IDENTITY field value using OUTPUT clause and this is possible only through the MERGE statement. Once this is done then we populate rest of the tables using corresponding temporary tables and uses a join to link to table variable on Grp value to get the generated identity value inserted to the tables.
At the end you can run a set of select statements in your table and see the populated data as below
As seen from the above data got populated to our tables as expected
This is a good approach you can use to extract data out of a multipart file and use it to populate a set of related tables in the database maintaining the referential integrity.
The main point to remember here is the generation of a GroupID value to group the similar Order rows together to make sure generated OrderHeaderID gets assigned correctly to each of them.
The package and sample file used in the illustration can be downloaded from the below link
Package :
Sample file:
Feel free to get back for any comments/clarification you may have on the above